
Dr. Benedikt Kämpgen

Peter Weiß

Krankenhäuser erleben einen permanenten Wandel ihrer existenziellen politischen und regionalen Rahmenbedingungen – aktuell z. B. durch die anstehende Krankenhausreform. Umso wichtiger sind für die Kliniken daher aktuelle Daten und Informationen, um Schritt halten zu können.
Nach dem Motto „Lernen von den Besten“ zeigen wir Ihnen, wie Benchmarking hierbei helfen kann. Der Vergleich bestimmter Performance-Indikatoren mit den Daten anderer Kliniken hilft Krankenhäusern dabei, Optimierungspotenziale zu erkennen und sich im zweiten Schritt an erfolgreich erprobten Prozessen oder Vorgehensweisen zu orientieren.
Beim Benchmarking werden in der Regel Statistik-Methoden eingesetzt (BI, Filterung, Aggregation, Data Cube). Mit steigender Datenmenge und -komplexität wird es jedoch immer aufwändiger für Anwender:innen, solche Statistiken zu erstellen und zu nutzen. Daher kommen hier mehr und mehr Algorithmen der Künstlichen Intelligenz ins Spiel. Was es mit diesen neuen Möglichkeiten auf sich hat und wie Klinken davon profitieren können, erfahren Sie in diesem Artikel.
Dem Krankenhaus bietet sich Benchmarking auf zwei Ebenen an:

Makro-Ebene: Eine Makro-Sicht ermöglicht den (regionalen) Vergleich mit anderen Krankenhäusern/Gesundheitsanbietern (über z. B. Bettenzahl, Anzahl der Fälle, Fachrichtungen, Versorgungsarten etc.). So lässt sich kontinuierlich überprüfen, ob das Leistungsspektrum aus wirtschaftlicher Sicht optimal aufgestellt ist und sich wichtige Parameter in die richtige Richtung entwickeln. Gleichzeitig können Fehlentwicklungen frühzeitig entdeckt und die Wirksamkeit von getroffenen Maßnahmen kontinuierlich überprüft werden.
Mikro-Ebene: Mikro-Benchmarking ist in vielen klinischen Bereichen denkbar. Da wir uns mit MetaKIS auf die Krankenhauskodierung und -abrechnung spezialisiert haben, fokussieren wir uns in diesem Artikel auf den Vergleich eines Patientenfalls mit der Kodierung ähnlicher Fälle in anderen Einrichtungen, die ebenfalls Benchmark-Daten liefern.


Aus den über 240 MetaKIS-Häusern werden täglich anonymisierte Daten in ein globales Benchmark-Profil übergeben – in einem Jahr entspricht das über drei Millionen Falldaten. Auf dem Benchmark-Profilserver werden die Daten gegroupt und die Profile errechnet. Am Ende werden die neuen Profile wieder an die teilnehmenden Kund:innen zurückgespielt. Die Profile und Benchmark-Daten sind somit tagesaktuell.
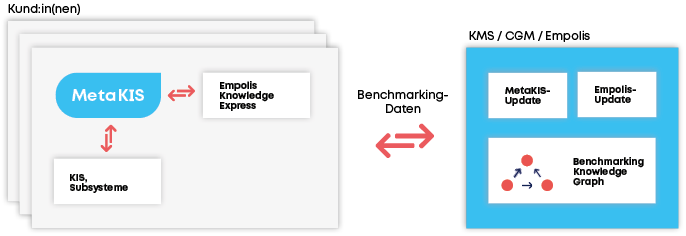
Der Benchmark-Datenserver erhält anonymisierte Falldaten aller Kund:innen, lernt daraus u. a. „Best Practices“ zur korrekten und effizienten Kodierung und spielt diese zurück an die Kund:innen (s. Abbildung 3).
Dazu erstellen MetaKIS und Empolis Knowledge Express Benchmarking-Daten auf den Systemen der Kund:innen. Diese Daten werden tagesaktuell zentral durch KMS und Empolis genutzt, um einen sog. Benchmarking Knowledge Graph zu erstellen und zu aktualisieren. Die Ergebnisse werden anschließend wieder an die Kundensysteme zurückgespielt, als Basis eines Wissensmanagers für Medizincontrolling und Kodierung.
Doch was genau ist der Benchmarking Knowledge Graph, wofür wird er genutzt und welche Rolle spielen hierbei Algorithmen der Künstlichen Intelligenz?
Für jeden Fall, der mit MetaKIS kodiert wird, enthält der Knowledge Graph (KG) einen Knoten. Jeder Fall enthält beliebig viele Eigenschaften, wie zum Beispiel das Geschlecht, die Kodierung, die Fallpauschale, die Dokumente mit ihren Inhalten usw. Ein KG eignet sich hierfür deshalb am besten, weil jeder Fall unterschiedlich viele Eigenschaften besitzen und er über seine Eigenschaften mit anderen Fällen beliebig stark verknüpft sein kann.
Alle Fälle im KG sind anonym, d. h. es lassen sich keine einzelnen Patient:innen identifizieren. So enthält der KG keine personenidentifizierenden Daten (z. B. Name, Geburtsdatum, Geburtsort), sondern nur strukturierte Standardkonzepte aus offenen Katalogen und Terminologien wie ICD, OPS, SNOMED-CT, LOINC oder RadLex. Freitextinformationen sind dagegen nicht enthalten, weil darin personenidentifizierende Merkmale genannt sein können.
Im KG kommen nun große Mengen an Expert:innen- und Daten-basiertem Wissen zusammen, aus denen man viel lernen kann:
Expertenbasiert wurde ein Beispiel-Fall etwa als „Weiblich“ deklariert. Auch wurden von Expert:innen (z. B. Kodierung, Ärzteschaft) Diagnosen festgelegt. Außerdem steckt Expertenwissen in den Katalogen, z. B. dass die Spontangeburt eine Art der Entbindung ist und dass ein Neugeborenes ein Kind ist.
Diese Konzepte ergeben sich entweder durch eine strukturierte Dokumentation oder durch nachträgliche Strukturierung mittels Natural Language Processing auf Dokumenten.
Datenbasiertes Wissen ist beispielsweise, dass Fälle mit Diagnose O80 zu 100 %
weiblich sind, dass KH1 im Durchschnitt pro Fall 2,3 Dokumente enthält (ein Rückschluss auf den digitalen Reifegrad der Krankenhäuser) oder dass Fälle mit einem dokumentierten Neugeborenen zu 60 % eine Kodierung O80 erhalten. Dieses Wissen steckt nicht explizit im KG, kann aber dort direkt abgefragt werden.
Der Mehrwert des KGs für Krankenhäuser liegt nun darin, Expert:innen- und datenbasiertes Wissen abzufragen und dann mit dem eigenen Krankenhaus zu vergleichen. Der KG liefert Antworten darauf, wie man als Krankenhaus näher am Benchmark liegen kann, d. h. Wissen über die Makro-Sicht und die Mikro-Sicht abfragen kann.
Für eine Vielzahl an Fragen, viele davon bereits erwähnt, lässt sich das Wissen leicht abrufen, z. B. in Form von Statistiken. Mit steigender Größe und Komplexität des KGs wird es jedoch immer aufwändiger, solche Statistiken bzw. Abfragen zu stellen und zu nutzen.
Hier trifft Benchmarking auf Künstliche Intelligenz. Denn für komplexere Fragestellungen werden Methoden der Künstlichen Intelligenz verwendet. Ein Beispiel: Nehmen wir an, wir haben einen neuen Fall. Auch dieser Fall hat ein Geschlecht, Dokumente etc. Wir möchten nun wissen, wie dieser Fall laut Benchmark KG kodiert werden sollte. Mit einer einfachen Abfrage auf dem KG ist es hier nicht mehr getan, die entsprechende Abfrage wäre viel zu komplex, um sie händisch zu erstellen. Stattdessen wollen wir die Abfrage automatisch erstellen und dafür Methoden der Künstlichen Intelligenz nutzen.
Was solche KI-Methoden können, kann man gut an einem sehr aktuellen Beispiel zeigen: ChatGPT. Dieser Chatbot wurde von OpenAI – sehr stark unterstützt durch Microsoft – entwickelt und in einer Beta-Version Ende 2022 veröffentlicht. ChatGPT ist vor allem auf offenen Daten aus dem World Wide Web sowie durch Menschen zum Lösen von allgemeinen Problemen/Aufgaben trainiert.
Wenn wir ChatGPT für die Kodierung nutzen, versteht der Chatbot die Fragen („Kodierung eines Nierensteins in beiden Nieren“), antwortet sehr ausführlich und nennt relevante Kodes. Insgesamt sehr beeindruckend, wozu dieser Chatbot in der Lage ist (s. Abbildung 4).

Bei einem genaueren Blick auf die Antwort erkennt man jedoch, dass ChatGPT nicht ganz korrekt ist. In dem Beispiel wird N20.2 empfohlen. Dieser Kode steht allerdings nicht für Steine in beiden Nieren, sondern in Niere und Ureter. Somit ist die Kodierempfehlung falsch. So eindrucksvoll ChatGPT ist, bei speziellen Aufgaben wie der Kodierung gibt es noch Besserungsbedarf.
Dessen Antworten sind zwar starrer als die von ChatGPT, da der Benchmarking Knowledge Graph nur anonymisierte strukturierte Daten enthält. Dafür sind die Antworten für die Dokumentation und Kodierung nützlicher. Dieser Bot fragt nach sinnvollen zusätzlichen Informationen, um die Empfehlungen noch besser zu machen. Auch wird die N20.0, also der Nierenstein, direkt an zweiter Stelle empfohlen. Wenn zudem ein Ureterstein beschrieben wird, nennt der Bot den richtigen Kode N20.2 direkt an zweiter Stelle (s. Abbildung 5).

Um zu testen, wie gut der Bot beim Kodieren ist, kann ein Krankenhaus ihm vergangene, bereits kodierte Fälle geben. Wenn der Bot in einem Krankenhaus selten korrekte Empfehlungen gibt, kann dies zwei Gründe haben: Entweder der Benchmark ist nicht vergleichbar mit dem Krankenhaus, sprich enthält nicht das notwendige Wissen. Oder die Dokumentation beim Krankenhaus ist nicht standardisiert genug für automatisierte Kodierempfehlungen.
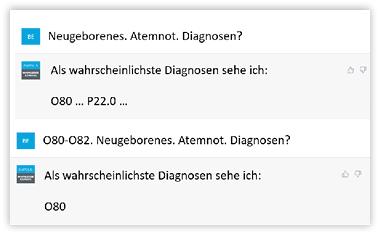
Denn je höher die Dokumentationsqualität, desto besser ist die Datengrundlage für Empfehlungen. Auch hier ein Beispiel (s. Abbildung 6). Wenn die Stichworte „Neugeborenes“ und „Atemnot“ verwendet werden, kann es sich um eine Mutter bei der Entbindung oder um ein Neugeborenes mit Atemproblemen handeln. Mit mehr Informationen und beispielsweise einem Hinweis darauf, dass es sich um eine Mutter bei der Entbindung handelt, tut sich das System deutlich leichter, passendere Empfehlungen auf Basis des Benchmarking Knowledge Graphs zu geben.
Wenn die richtige Dokumentationsqualität, der Benchmarking Knowledge Graph und entsprechend leistungsfähige KI-Methoden kombiniert genutzt werden, entsteht ein enormes Potenzial: Es wird damit möglich sein, bestimmte Fälle vollautomatisch zu kodieren. In Folge kann das Personal in den Bereichen Medizincontrolling und Kodierung deutlich sinnvoller eingesetzt werden, um sich komplexeren Tätigkeiten wie z. B. Simulationen zu widmen.
Benchmarking heißt „Lernen von den Besten“ und ist unverzichtbar für Krankenhäuser im modernen Gesundheitswesen. Die Basis hierfür ist ein riesiger Knowledge Graph, so wie MetaKIS ihn seit Jahren tagesaktuell erstellt. In eigenen Statistiken und Abfragen hat dies bereits einen hohen Mehrwert für Krankenhäuser. Sowohl in einer Makro-Sicht auf das Krankenhaus im Vergleich zu anderen Krankenhäusern als auch in einer Mikro-Sicht auf einzelne Patient:innen, wie sie im Vergleich zu anderen Krankenhäusern kodiert werden. Je komplexer die Frage, zum Beispiel nach der korrekten Kodierung, desto mehr sind hierzu Methoden der Künstlichen Intelligenz notwendig, um die richtigen Muster zu erkennen und Empfehlungen zur Dokumentation sowie Kodierung zu geben. Mit MetaKIS profitieren Sie von einem DRG-Multitool, das Sie bei der Kodierung intelligent unterstützt und in naher Zukunft sogar Möglichkeiten für eine Vollautomatisierung bietet.
Telefon: +49 89 66 55 09-0
Telefax: +49 89 66 55 09-55
Support: +49 89 66 55 09-45

