Von den Anfängen bis zur Verbesserung von Arbeitsabläufen in der Gesundheitsversorgung
Eine Perspektive von Prof. Dr. ir. Wil van der Aalst
Das suprafluide Krankenhaus - eine Utopie?
Process Mining-Verfahren nutzen Daten von Ereignissen, um darzustellen, was Menschen, Maschinen und Organisationen real tun. Process Mining liefert neue Einblicke in Leistungs- und Konformitätsprobleme und hilft, diesen entgegenzusteuern. Der Einsatz von Process Mining in der Praxis ist in den vergangenen Jahren rapide gestiegen. Zu Beginn lag der Fokus auf verhältnismäßig strukturierten Verfahren wie Purchase-to-Pay (P2P) und Order-to-Cash (O2C). Selbst anhand dieser einfachen und anscheinend gut strukturierten Prozesse kann Process Mining Unstimmigkeiten in der Umsetzung (Nachbesserung, Verzögerungen) verringern, indem die kostenintensivsten Abweichungen aufgezeigt werden.
Angesichts dieser Erfolge wird Process Mining nun auch weltweit für weniger strukturierte Verfahren genutzt. Auch wenn Process Mining für solche Verfahren mehr Herausforderungen bedeutet, sind die Potenziale für eine Verbesserung höher. Dies gilt auch für die Nutzung von Process Mining in der Gesundheitsversorgung.
Krankenhäuser und andere Anbieter von Gesundheitsleistungen sind in der täglichen Patientenversorgung vielschichtigen Herausforderungen ausgesetzt, was wegen der unvorhersehbaren Natur von Behandlungs- und Diagnoseverfahren teils unvermeidlich ist. Trotzdem wird anerkannt, dass auch im Gesundheitswesen Raum für Prozessverbesserungen besteht. Aus diesem Grund ist es überaus sinnvoll, Process Mining in Gesundheitsorganisationen anzuwenden.
Was ist Process Mining?
Der Eingangswert für Process Mining besteht aus einem Ereignisprotokoll. Durch ein Ereignisprotokoll wird ein Verfahren aus einem bestimmten Blickwinkel heraus betrachtet. Jedes Ereignis im Protokoll bezieht sich auf (1) eine einzelne Prozessinstanz (genannt Fall), (2) eine Aktivität und (3) einen Zeitstempel. Daneben kann es weitere Ereignismerkmale mit Bezug auf Ressourcen, Abteilungen, Kosten etc. geben, die aber optional sind.
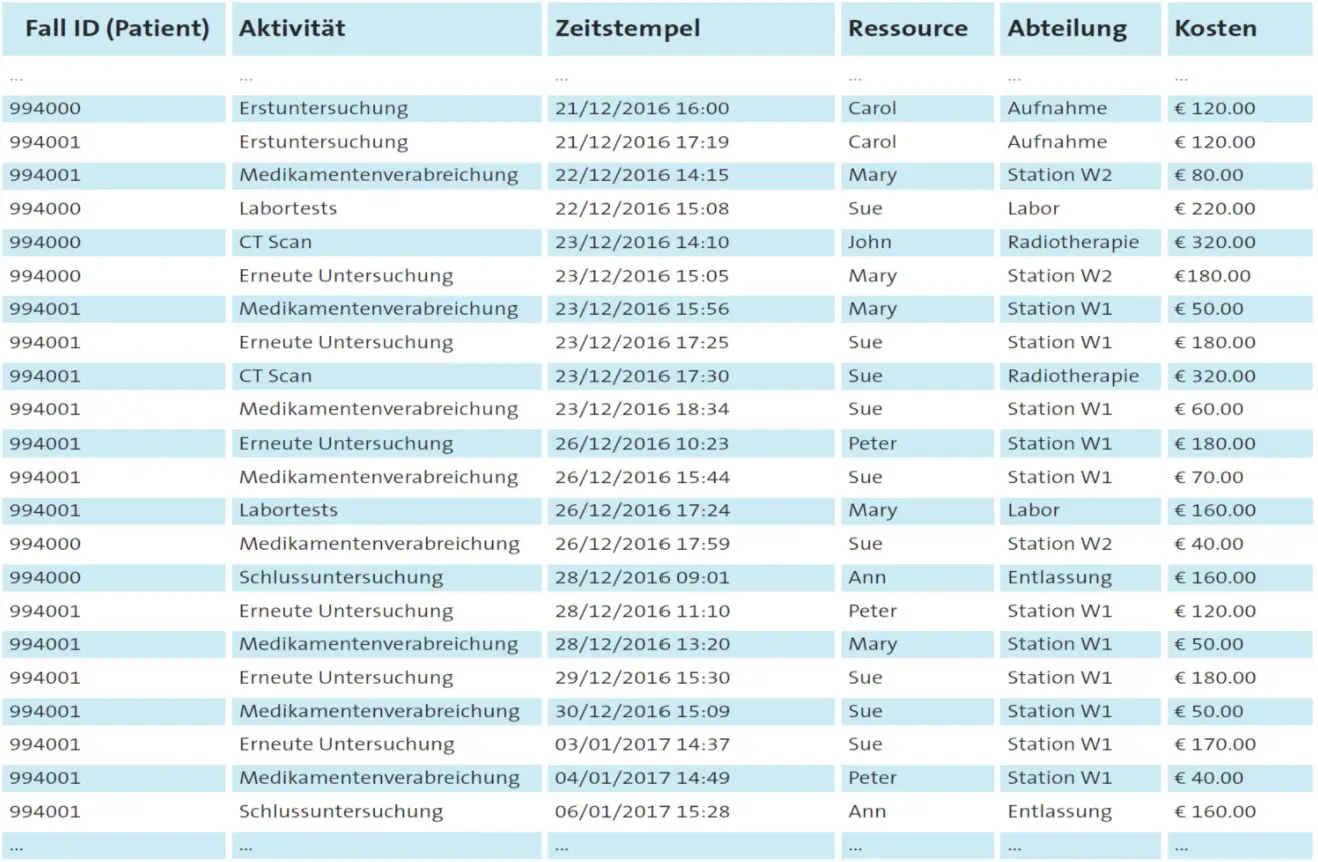
Tabelle 1: Kleiner Ausschnitt eines größeren Ereignisprotokolls (nur 22 von insgesamt 58.624 Ereignissen sind angezeigt) für einen fiktiven Behandlungsprozess mit Ereignisdaten von 5.000 Patienten.
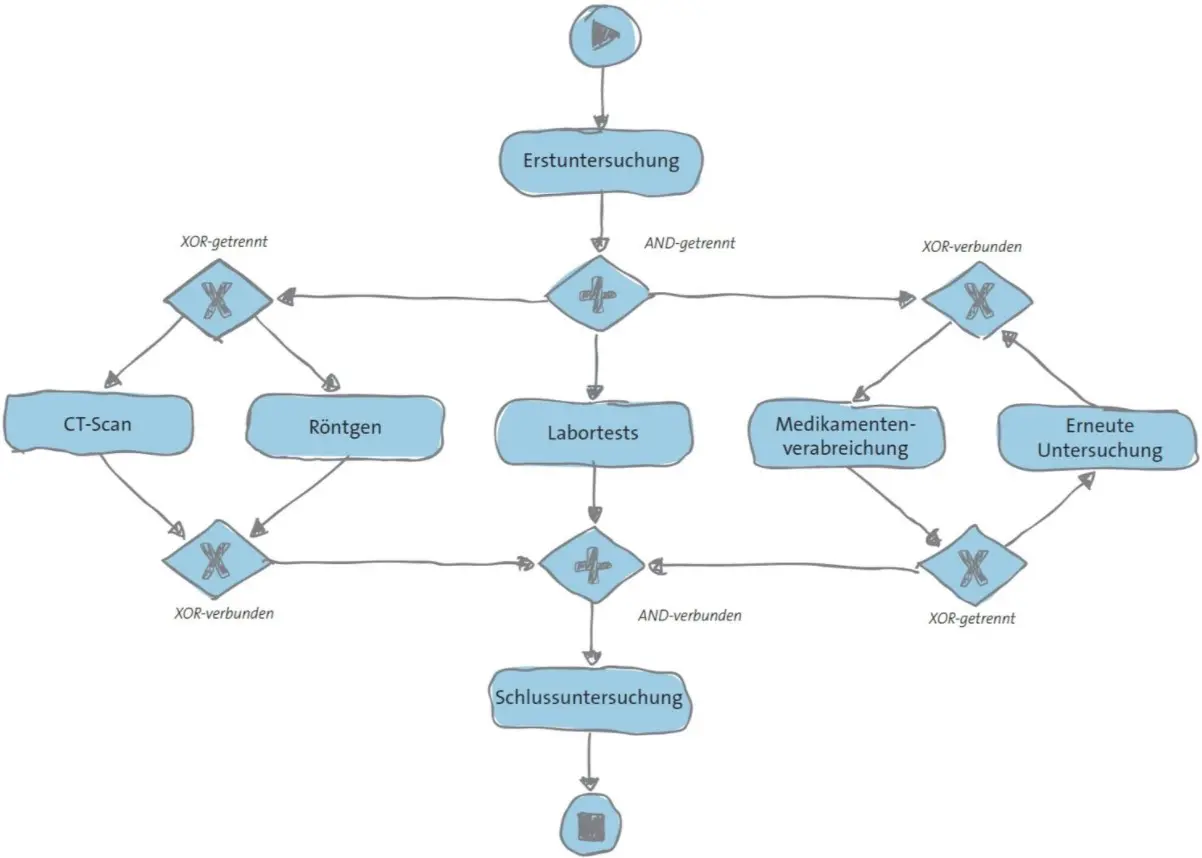
Um eine Vorstellung von einem Ereignisprotokoll zu erhalten, betrachten wir Tabelle 1. Die Aufstellung zeigt fiktive Daten in Verbindung mit zwei Patienten (994000 und 994001). Die ersten drei Spalten beschreiben Pflichtdaten (Fall-ID, Aktivität und Zeitstempel). Mit etwas Einsatz können solche Daten aus jedem Informationssystem herausgefiltert werden, die Umsetzungsprozesse unterstützen (einschließlich der Informationssysteme im Gesundheitswesen). Im Process Mining werden diese Ereignisdaten genutzt, um eine Vielfalt von prozessbezogenen Fragen beantworten zu können. Process Mining-Methoden wie Prozessextraktion, Konformitätskontrolle, Modellerweiterung und operative Unterstützung können für die Leistungs- und Konformitätsverbesserung herangezogen werden. Das Verfahrensmodell, wie in Schaubild 1 dargestellt, veranschaulicht die verschiedenen Konzepte. Das Modell zeigt sieben Aktivitäten und sechs sogenannte Gateways, um die Anordnung von Aktivitäten zu präzisieren.
Schaubild 1: Verfahrensmodell zur Beschreibung eines Behandlungsprozesses. Das Verfahren beginnt mit der Aktivität Erstuntersuchung und endet mit der Aktivität Schlussuntersuchung. Zwischen diesen beiden Aktivitäten bestehen voneinander unabhängige parallel laufende Teilbereiche: (1) die Wahl zwischen der Aktivität CT Scan und der Aktivität Röntgen, (2) Aktivität Labortests und (3) eine mögliche Schleife, die die Verabreichung von Medikamenten oder eine erneute Untersuchung beinhaltet.
In der Regel kennen wir den zugrunde liegenden Prozess nicht bzw. er unterscheidet sich von unseren Erwartungen. Die Extraktion der tatsächlichen Prozesse beginnt mit rohen Ereignisdaten und fußt auf den Erfahrungen der beispielhaften Ereignisse.
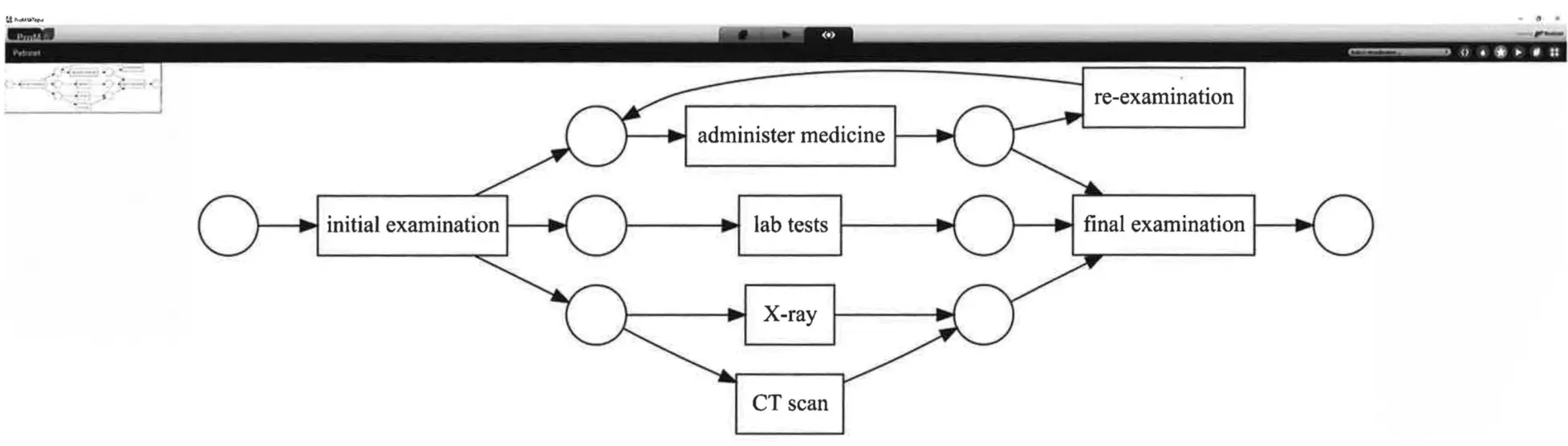
Schaubild 2 bildet ein Modell für einen Behandlungsprozess (dargestellt in Form eines Petri-Netzes) auf Grundlage der Erkenntnisse aus dem Ereignisprotokoll in Tabelle 1 (unter Nutzung aller 58.624 Ereignisse) ab, bei Anwendung einer Variante des sogenannten Alpha-Algorithmus, umgesetzt in ProM. Die durch das Petri-Netz beschriebene Handlungsweise ist identisch mit der in Schaubild 1. Dabei wurde nichts modelliert, das Modell basiert auf Erkenntnissen aus Daten von 5.000 Patienten. Der Alpha-Algorithmus war der erste Algorithmus, durch den ein durchgängiges Verfahrensmodell mit gleichzeitigem Zugriff extrahiert wurde.
Schaubild 2: Petri-Netz-Modell automatisch extrahiert auf Grundlage von Erkenntnissen aus dem Ereignisprotokoll der Tabelle 1 (bei Nutzung aller 58.624 Ereignisse) unter Anwendung des Alpha-Algorithmus, umgesetzt in ProM.
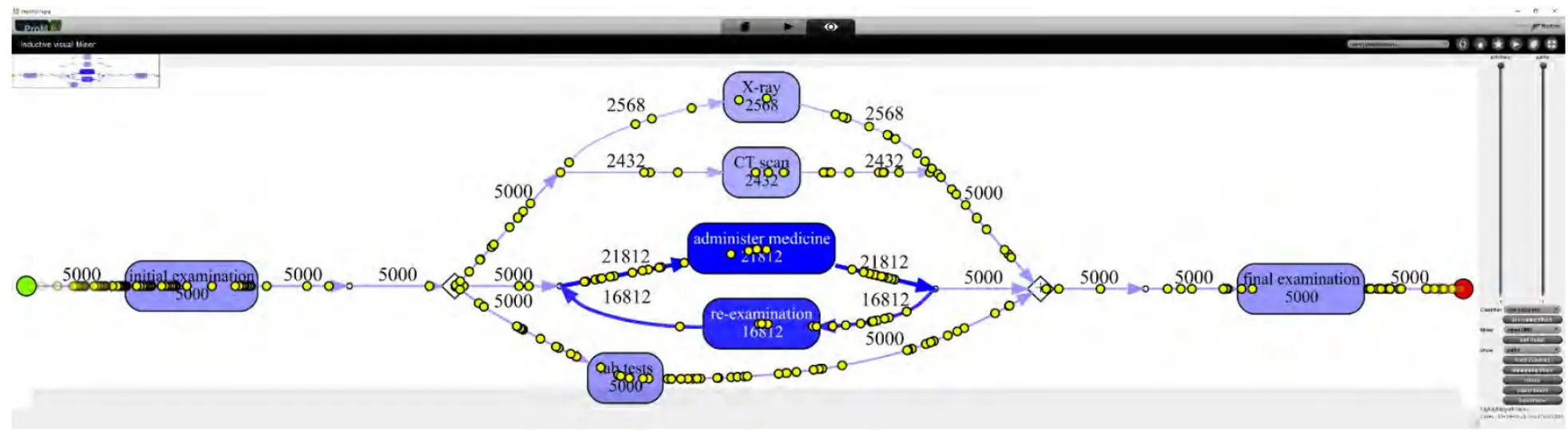
Dieser Algorithmus bringt viele Beschränkungen mit sich. Glücklicherweise gibt es neuere Algorithmen, die widerstandsfähiger und in der Lage sind, selten auftretende bzw. außergewöhnliche Reaktionen zu verarbeiten. Schaubild 3 zeigt ein Verfahrensmodell, das aus der Anwendung des Inductive Miners entstand. Bei diesem einfachen Beispiel bleibt die Handlungsweise gleich. Schaubild 3 verdeutlicht allerdings die Häufigkeit von Schleifen und Knoten und veranschaulicht den Ablauf für 5.000 Patienten (siehe gelbe Punkte). Jeder Punkt steht für einen Patienten und kann eingefärbt werden, um Unterschiede zwischen Patientengruppen sichtbar zu machen.
Schaubild 3: Verfahrensbaum entwickelt aus dem Ereignisprotokoll von Tabelle 1 (bei Nutzung aller 58.624 Ereignisse) unter Anwendung von Inductive Miner, umgesetzt in ProM.
Durch die Verbindung zwischen den Verfahrensmodellen und den Ereignisdaten kann im Modell eine „Realität“ nachvollzogen werden (wie in Schaubild 3 dargestellt). Diese kann genutzt werden, um Engpässe zu verdeutlichen, zu erklären und zu prognostizieren. So wird deutlich, dass die Röntgenabteilung nicht zu akzeptierende Wartezeiten für bestimmte Gruppen von Patienten verursacht.
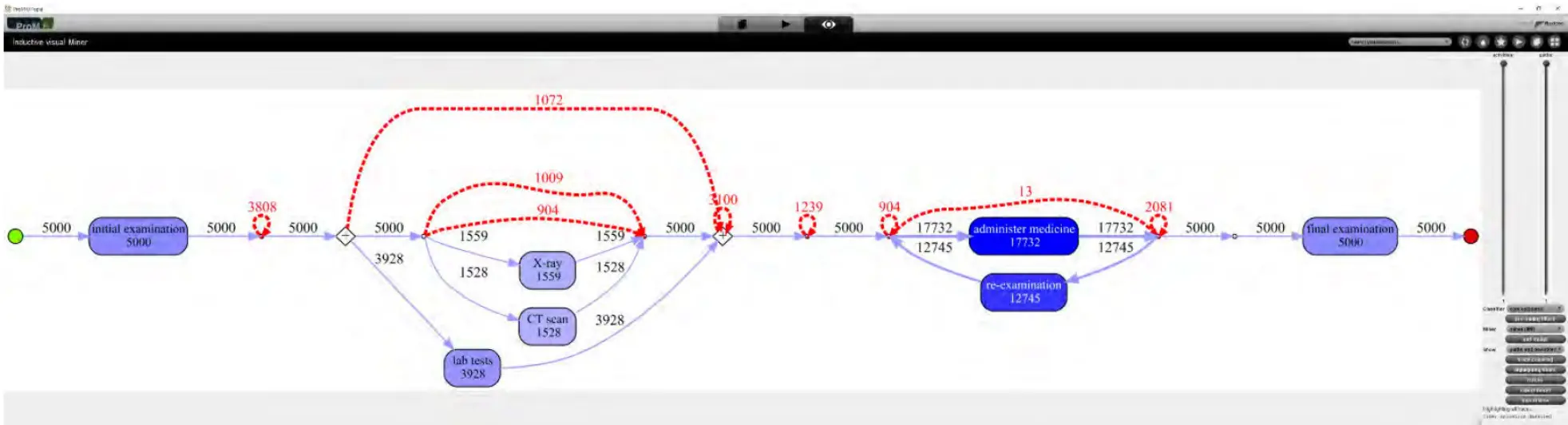
Über die Zuordnung von Ereignisdaten zu einem extrahierten Modell hinaus, kann die „Realität“ auch durch ein normatives Modell nachvollzogen werden (handgemacht). Auf diesem Weg ist es möglich, die Unterschiede zwischen einem geplanten bzw. erwarteten Verfahren und dem realen Verfahren sichtbar zu machen. Schaubild 4 stellt die Durchführung einer Konformitätsprüfung dar. Genutzt wird ein Standardmodell (in blau), welches festlegt, dass Medikamente erst nach Labortests und Röntgen oder CT-Scan verabreicht werden können. Die rot gestrichelten Bögen kennzeichnen die Unterschiede zwischen dem aktuellen Verfahren und dem handgemachten normativen Verfahrensmodell. Damit kann die Schwere der Abweichungen erfasst und automatisch eine Ursachenanalyse für wiederholt auftretende Abweichungen vorgenommen werden. Dies stellt einen Weg dar, medizinische Leitlinien zu bestätigen und Konformität sicher zu stellen.
Schaubild 4: Ergebnisse einer Konformitätsprüfung verdeutlichen die Unterschiede zwischen den Ereignisprotokollen und dem normativen Modell, gekennzeichnet in blau. Die rot gestrichelten Bögen kennzeichnen die Abweichungen und die roten Zahlen die Häufigkeit für jede Abweichung.
Wie sieht der Einstieg aus?
Process Mining kann genutzt werden, um herauszufinden, was real stattfindet. In der Folge können die Ereignisdaten genutzt werden, um Leistungs- und Konformitätsprobleme anzugehen. Derzeit gibt es mehr als 30 kommerzielle Angebote für Process Mining-Software (z. B. Celonis®, Disco, ProcessGold, myInvenio, PAFnow, Minit, QPR, Mehrwerk, Puzzledata, LanaLabs, StereoLogic, Everflow, TimelinePI, Signavio und Logpickr). Und dies neben den Open Source-Tools wie ProM.
Kommerzielle Programme nutzen in der Regel Directly Follows Graphs (DFGs), d. h. eine sehr einfache Darstellungsart für Prozessentwicklung, bei der die Knotenpunkte Aktivitäten sind und die Bögen andeuten, dass eine Aktivität der anderen folgt. Die entstehenden Schaubilder sind einfach nachzuvollziehen und hilfreich für ein erstes Verstehen des Prozesses. Trotzdem erscheint DFGs für eine Leistungs- und Konformitätsanalyse nicht geeignet. Aktivitäten, die keiner festen Reihenfolge unterliegen (z. B. wegen Gleichzeitigkeit), führen zu Spaghetti-ähnlichen DFGs mit Windungen, selbst wenn Aktivitäten überwiegend gleichzeitig durchgeführt werden. Im DFG unseres fortlaufend genutzten Beispiels sind die fünf zentralen Aktivitäten vollständig in beide Richtungen miteinander verbunden (nicht abgebildet).
Das Modell suggeriert somit zahlreiche Schleifen, obwohl nur eine vorhanden ist. DFGs können durch die Nutzung von häufigkeitsbezogenen Schwellenwerten vereinfacht werden (um das Modell zu vereinfachen, sollten weniger relevante Bögen entfernt werden). Trotzdem könnte es zu vielfältigen Interpretationsproblemen führen. Deshalb werden in einigen Programmen Petri-Netze oder BPMN-Modelle für Konformitätsprüfungen oder für anspruchsvollere Formen der Extrahierung genutzt. Es ist hilfreich, sich bei der Anwendung von Process Mining dieser Probleme bewusst zu sein. Über die Software hinaus werden Ereignisdaten benötigt. In einem Krankenhausinformationssystem ist eine Vielfalt von Tabellen enthalten, die den vorher beschriebenen Anforderungen entspricht. In den meisten Tabellen eines Krankenhausinformationssystems gibt es eine Spalte mit Referenz zur Patienten-ID und ein oder mehrere Spalten mit Terminen und / oder Zeitstempel.
Nichtsdestotrotz ist es grundsätzlich nicht immer so leicht, die relevanten Daten für einen spezifischen Behandlungsprozess aufzufinden. Aber wenn die Daten einmal gefunden und extrahiert wurden, ist es einfach, Process Mining anzuwenden. Zu Beginn von Process Mining-Projekten werden 80 Prozent der Zeit für die Datenentnahme verwendet und nur 20 Prozent für die eigentliche Analyse. Bei einer längerfristigen Anwendung von Process Mining stellt sich dies nur als Anfangsproblem dar, danach liegt der Schwerpunkt auf der täglichen oder wöchentlichen Analyse und auf der Verbesserung der Verfahren. Die Fülle von Process Mining-Tools und Ereignisdaten ermöglicht es, Process Mining in vielen Feldern einzusetzen, einschließlich der Gesundheitsversorgung. Und es ist relativ einfach, damit zu beginnen. Um Process Mining erfolgreich anwenden zu können, muss in Fachwissen und Datenverwaltung investiert werden. Es ist wahrscheinlich, dass durch Process Mining auch Probleme im Bereich der Datenqualität auffallen. Diese müssen allerdings sowieso gelöst werden und sollten deshalb einen Fortgang nicht blockieren. Außerdem ist es sinnvoll, die Anwendung kontinuierlich umzusetzen, um den größten Nutzen aus Process Mining zu erhalten. Gleiche Analysen können mit neuen Ereignisdaten täglich durchgeführt werden, und Erkenntnisse sollten in Maßnahmen zur Verbesserung der Situation übersetzt werden. Process Mining kann auch ernsthafte Probleme in der Organisation offenlegen. Es gibt möglicherweise Interessengruppen, die keine Transparenz möchten. Demzufolge ist es von besonderer Bedeutung, die Unterstützung der höchsten Managementebene für Process Mining-Projekte zu sichern, um diese für die Organisation zum Erfolg zu führen.
Vielen Dank für diesen spannenden Einblick in die Welt der Prozesse, Herr Prof. Dr. ir. Wil van der Aalst!
Mehr erfahren?
Es gibt einen Coursera Open-Online-Kurs zu Process Mining (https://www.coursera.org/learn/processmining), der schon von 120.000 Teilnehmern belegt wurde.
Für eine tiefergehende, aber allgemeine Einführung nutzen Sie das Buch „Process Mining: Data Science in Action“ (https://www.springer.com/978-3-662-49850-7).
Das Buch „Process Mining in Healthcare: Evaluating and Exploiting Operational Healthcare Processes" (https://www.springer.com/978-3-319-16071-9) bietet eine Einführung in Process Mining-Anwendungen im Gesundheitswesen. Das Buch beinhaltet ebenfalls ein Referenzmodell, das die üblichen Ereignisdaten aufzeigt, die in Krankenhäusern erhältlich sind,
– AUTOR
Prof. Dr. ir. Wil van der Aalst
Prof. Dr. ir. Wil van der Aalst begann 1999 seine aktive Arbeit im Bereich Process Mining. Anlass war die Feststellung, dass die für Simulationsstudien und die Umsetzung von Arbeitsabläufen angewendeten Prozessmodelle oft von den tatsächlichen Prozessen abwichen. Aus diesem Grund erschien es sinnvoll, von Ereignisdaten auszugehen und nicht von manuell erarbeiteten Modellen. Darüber hinaus erschien die Fragestellung des Erkenntnisgewinns bei durchgehender Prozessbetrachtung auf Grundlage von Verhaltensbeispielen aus wissenschaftlicher Perspektive sehr interessant.
Prof. Dr. ir. Wil van der Aalst ist Ordinarius an der Rheinisch-Westfälischen Technischen Hochschule Aachen und leitet dort den Bereich Process and Data Science (PADS). Er ist gleichzeitig für das Fraunhofer-Institut für Angewandte Informationstechnik (FIT) tätig, wo er die Process Mining-Initiative des Instituts leitet. Seine Forschungsinteressen umfassen Process Mining, Petri-Netze, Geschäftsprozessmanagement, Workflow-Management, Prozessmodellierung und Prozessanalyse. Wil van der Aalst veröffentlichte mehr als 200 Artikel in Fachzeitschriften, 20 Bücher (als Autor und Herausgeber), 450 Fachveröffentlichungen von Konferenzen bzw. Workshops und 65 Buchkapitel. Neben der Mitarbeit in Redaktionsgremien von zehn wissenschaftlichen Fachzeitschriften ist er für mehrere Unternehmen beratend tätig, u. a. für Fluxicon, Celonis®, Processgold und Bright Cape. Van der Aalst erhielt Ehrendoktorwürden von der Moskauer Higher School of Economics (Prof. h. c.), der Tsinghua Universität und der Universität von Hasselt (Dr. h. c.). Er ist außerdem gewähltes Mitglied der Königlich Niederländischen Akademie der Wissenschaften, der Königlichen Niederländischen Gesellschaft für Wissenschaften und der Academy of Europe. 2017 wurde ihm die Alexander von Humboldt-Professur verliehen.
Wir nutzen Cookies auf unserer Website. Einige von ihnen sind essenziell, während andere uns helfen, diese Website und Ihre Erfahrung zu verbessern.Wenn Sie unter 16 Jahre alt sind und Ihre Zustimmung zu freiwilligen Diensten geben möchten, müssen Sie Ihre Erziehungsberechtigten um Erlaubnis bitten.Wir verwenden Cookies und andere Technologien auf unserer Website. Einige von ihnen sind essenziell, während andere uns helfen, diese Website und Ihre Erfahrung zu verbessern.Personenbezogene Daten können verarbeitet werden (z. B. IP-Adressen), z. B. für personalisierte Anzeigen und Inhalte oder Anzeigen- und Inhaltsmessung.Weitere Informationen über die Verwendung Ihrer Daten finden Sie in unserer Datenschutzerklärung.Sie können Ihre Auswahl jederzeit unter Einstellungen widerrufen oder anpassen.
Wenn Sie unter 16 Jahre alt sind und Ihre Zustimmung zu freiwilligen Diensten geben möchten, müssen Sie Ihre Erziehungsberechtigten um Erlaubnis bitten.Wir verwenden Cookies und andere Technologien auf unserer Website. Einige von ihnen sind essenziell, während andere uns helfen, diese Website und Ihre Erfahrung zu verbessern.Personenbezogene Daten können verarbeitet werden (z. B. IP-Adressen), z. B. für personalisierte Anzeigen und Inhalte oder Anzeigen- und Inhaltsmessung.Weitere Informationen über die Verwendung Ihrer Daten finden Sie in unserer Datenschutzerklärung.Hier finden Sie eine Übersicht über alle verwendeten Cookies. Sie können Ihre Einwilligung zu ganzen Kategorien geben oder sich weitere Informationen anzeigen lassen und so nur bestimmte Cookies auswählen.